3.3 Yarn模式
# yarn模式
yarn上部署的过程是:
- 客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。
- 在这些容器上,Flink会部署JobManager和TaskManager实例,从而启动集群。
- Flink根据运行在JobManager上的作业所需的Slot数量动态分配TaskManager资源。
# 相关准备和配置
将Flink任务部署到Yarn集群之前,需要先安装Hadoop集群。
有两种方式配置,第一种是将flink-shaded-hadoop3-uber-blink-xxx.jar放到Flink_HOME的lib目录下,这种方式比较方便,但是需要自己去找对应适配好的Flink-Hadoop对应版本,如果没有需要自己编译维护。第二种是指定Hadoop集群的环境变量,也是推荐使用第二种方式,具体配置步骤如下:
- 配置环境变量,增加环境变量配置如下:
编辑环境变量配置文件,此处是在profile.d目录下专门建立一个文件存放环境变量,因此vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
2
3
4
更改配置后,记得生效一下source /etc/profile
- 启动hadoop集群,包括HDFS和YARN

到这里,相关的准备和配置就完成了。
# 会话模式部署
Yarn的会话模式与Standalone模式的集群策略有所不同,需要首先申请一个YARN Session来启动Flink集群,具体步骤如下:
- 启动集群
执行命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群
bin/yarn-session.sh -nm test -d
执行命令的参数都可以通过如下命令查看
bin/yarn-session.sh --help

看不懂的参数就翻译下咯
注意:FLink从1.11.0版本后不在使用-n参数和-s参数分别指定TaskManager数量和slot数量,YARN会按照需求动态分配TaskManager和slot。所以从某种意义上来说,YARN的会话模式也不会把集群资源固定,同样也是动态分配的。
这个也好验证,使用YARN Session提交一个作业,再把作业停掉,等待个1分钟这样,会发现资源被释放了
- 提交作业
有两种方式提交,一种是通过Web UI进行提交
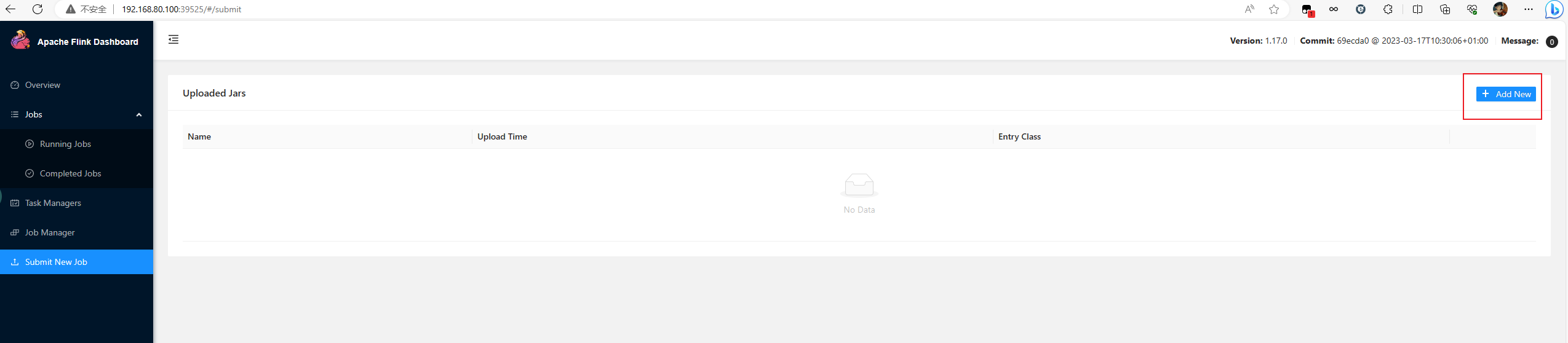
还有一种就是通过命令行的方式进行提交,也是比较建议的方式,执行如下命令即可
bin/flink run -c org.apache.flink.streaming.examples.windowing.TopSpeedWindowing examples/streaming/TopSpeedWindowing.jar

如上就发现作业成功运行了,这里我们可以使用-m参数显示的指定YARN Session地址,但是为什么我们没指定也能提交呢,原因在这里,日志里边有个/tmp/.yarn-properties-root

这个文件里边就保存了最新的YARN 集群的一些记录信息,因此,如果你遇到了启动YARN集群提交作业后想再使用Standalone模式任务会发现提交不了,这时候就应该把这个文件删除掉就行了

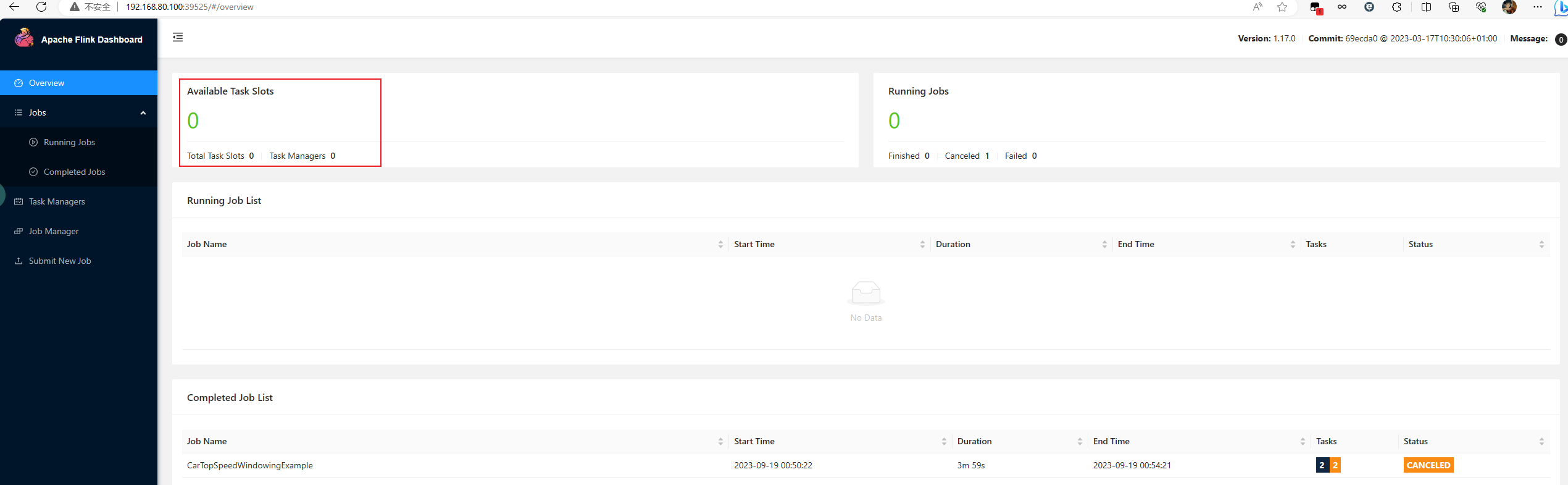
刚才在上面说到一个YARN Session也支持动态分配资源了,正好来实验一下,如下图,当作业被停止后

会发现slot的数量从1变成0了,这时候集群中多了一个slot的资源,大概等了约半小时,这个slot被释放了,这时候YARN Session中没有slot了,这就说明,YARN的会话模式也不会把集群资源固定,同样也是动态分配的
# 单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。
这种方式过时了,后面会被应用模式部署渐渐替代,当然,在较老Flink版本当中还是经常使用的
1, 执行命令提交作业
bin/flink run -d -t yarn-per-job -c org.apache.flink.streaming.examples.windowing.TopSpeedWindowing examples/streaming/TopSpeedWindowing.jar
如果启动过程中报错如下异常不要慌,作业其实已经正常提交了,且这个报错也给出了解决方案了,去配置文件里忽略一些就行
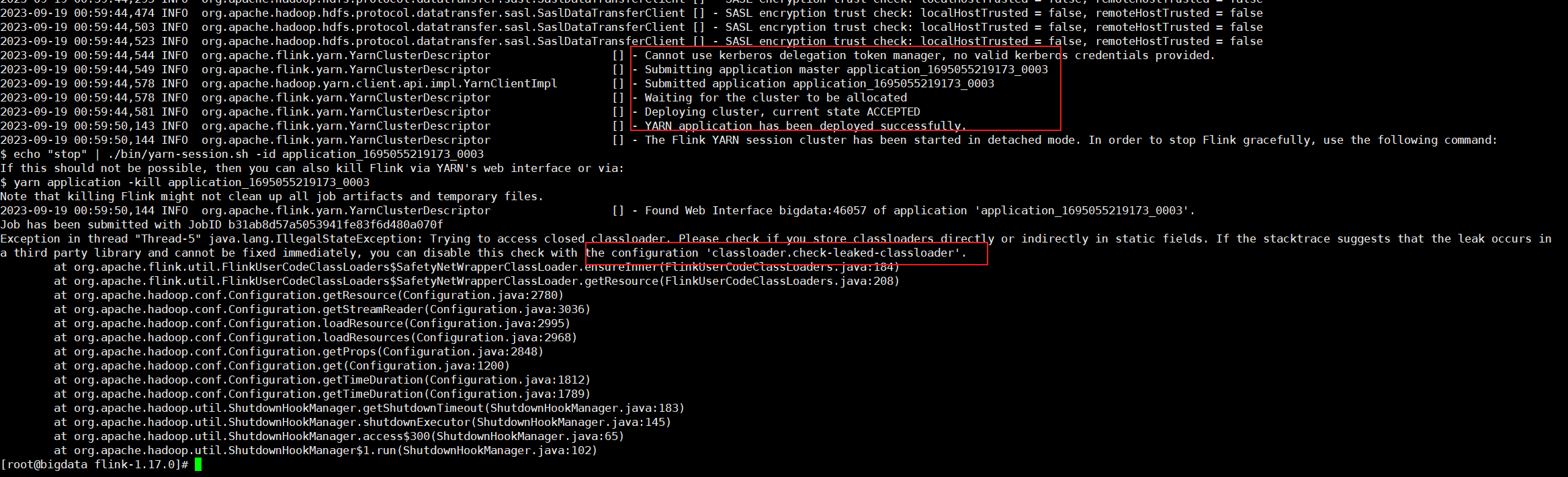
修改conf/flink-conf.yaml,添加如下配置
classloader.check-leaked-classloader: false
- 查看或者取消作业,命令如下:
说明:这里先提一点,cancel取消作业不会保存savepoint,stop停止作业会保存savepoint,后面会验证
# 查看application下运行的flink作业
bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
# 停止flink作业 需要指定jobId
bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
2
3
4
5
当然也可以暴力停止,或者页面上点击cancel也行
yarn application -list
yarn application -kill appId
2
3
# 应用模式部署
应用模式部署直接执行flink run-application命令即可
# 本地提交
作业jar包、flink的lib目录下的文件在本地
相关执行参数可以查询
bin/flink run-application --help
- 执行命令行提交作业
bin/flink run-application -t yarn-application -c org.apache.flink.streaming.examples.windowing.TopSpeedWindowing examples/streaming/TopSpeedWindowing.jar

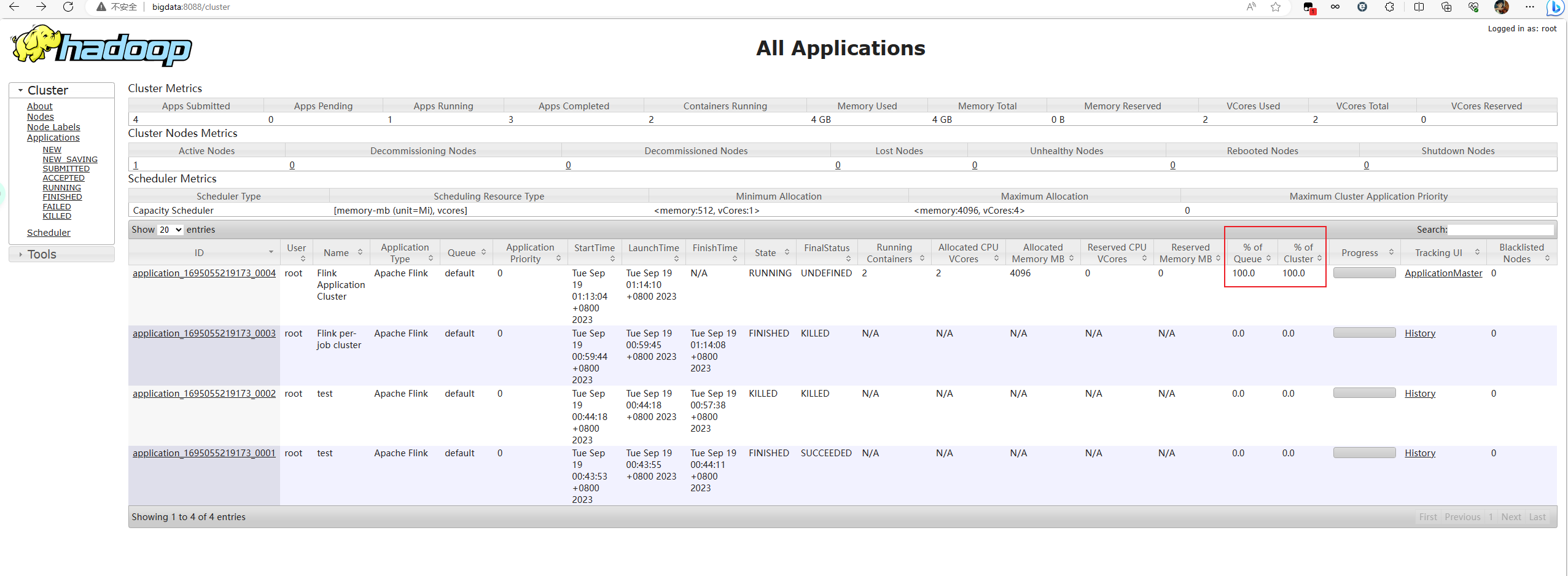
同时也可以去Yarn的Web UI上查看,这里提一嘴,如下发现这个任务把队列的资源使用满了,如果这时候新的任务也是提交到这个队列上的话,那就会一直是ACCEPT状态,解决方法是要不加大YARN资源,要么换个队列提交,或者更改YARN队列的资源容量
- 停止作业
停止作业的方式和单作业模式一样,往上翻翻就看到咯。
# 上传Hadoop提交
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程,先把jar包和所需要的lib依赖上传到hdfs上,可以大大的降低客户端传输作业的资源提高提交效率。
- 上传flink的lib和plugins到HDFS路径上
hadoop fs -mkdir /flink-dist
hadoop fs -put lib/ /flink-dist
hadoop fs -put plugins/ /flink-dist
2
3
- 上传作业jar包到HDFS
hadoop fs -mkdir /flink-jars
hadoop fs -put FlinkTutorial-1.0-SNAPSHOT.jar /flink-jars
2

- 提交作业
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://bigdata:8020/flink-dist" -c org.apache.flink.streaming.examples.windowing.TopSpeedWindowing hdfs://bigdata:8020/flink-jars/TopSpeedWindowing.jar
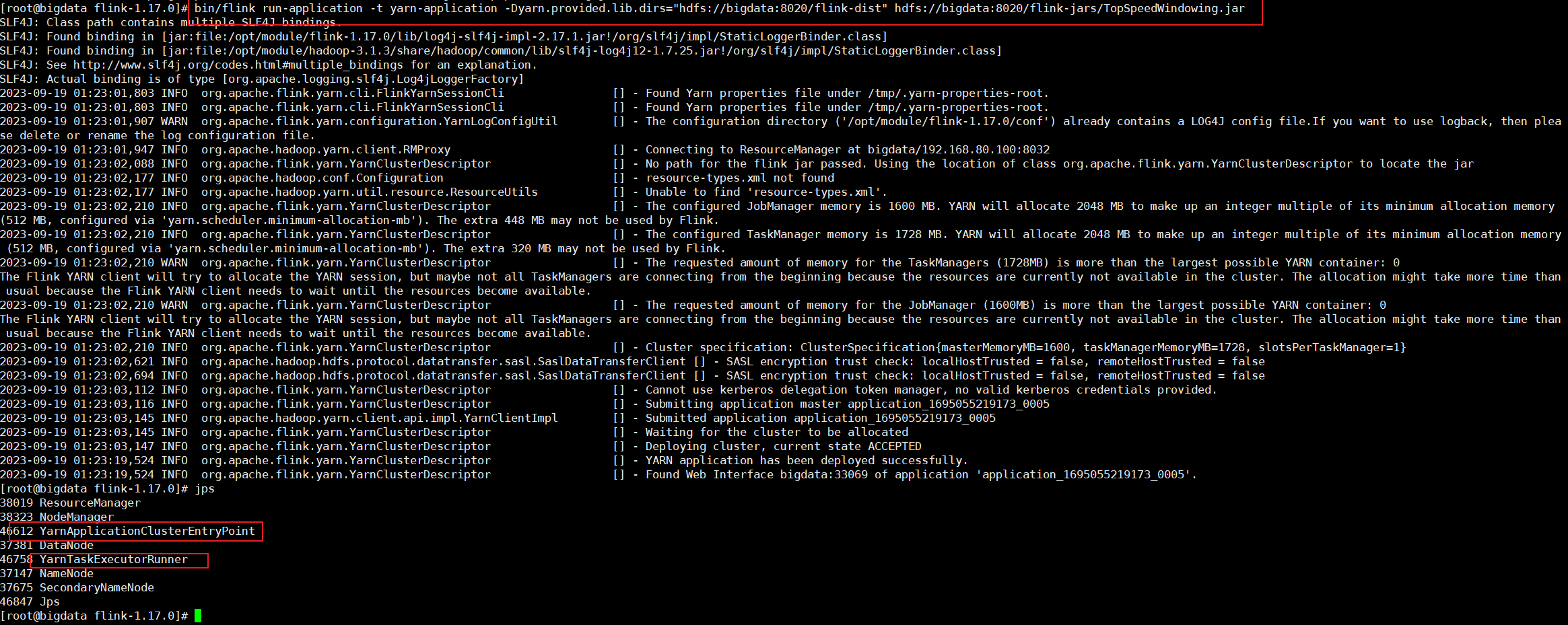
这种方式下,Flink本身的依赖和作业jar包预先上传到HDFS上,而不需要每次单独发送到集群,这就使得作业提交非常的轻量,因此作业提交效率也是相对较快的。